Architecture
Technology Stack
- PySide6 - Cross-platform GUI
- qfluentwidgets - Modern Qt Theming Framework
- Transformers - Model loading and inference
- Ultralytics / YOLOv9 – Region and line segmentation
- PyMuPDF (fitz) – PDF rasterization
- OpenCV / scikit-image / Pillow – Image preprocessing
- python-docx / Qt PDF – Export to DOCX and PDF
- SQLAlchemy / SQLite - Job Database
- Nuitka – Compilation to native standalone executable
Recognition Pipeline
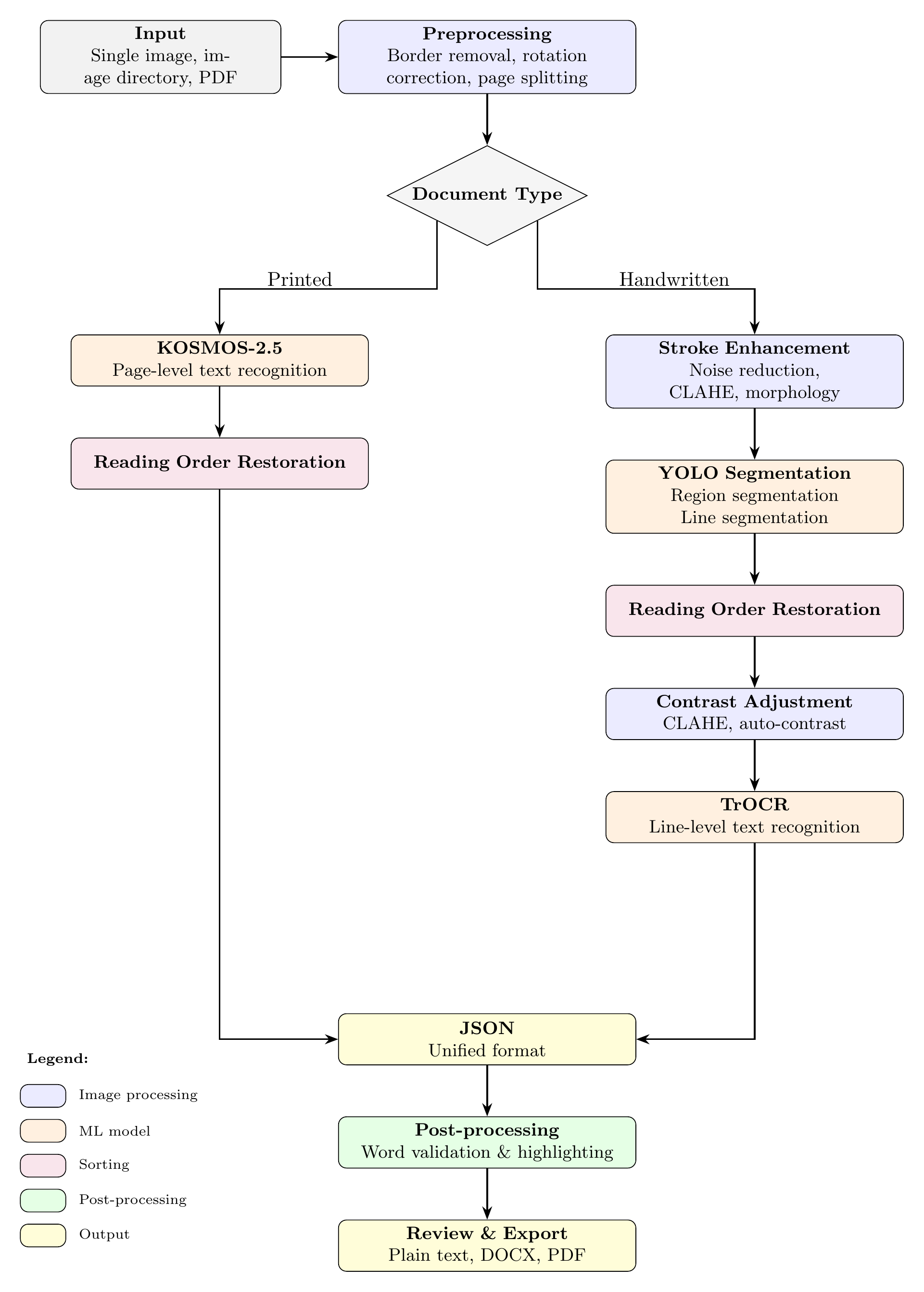 Textum OCR/HTR processing pipeline architecture
Textum OCR/HTR processing pipeline architecture
Internal Data Representation
- Jobs and their statuses are saved in an SQLite database.
- Each job's content is saved as a JSON file in the working directory, including the recognized text with bounding boxes.
- Both the handwritten and printed pipeline produce the same JSON format, to make post-processing easier.
- The processed images are also saved in the working directory.
Job JSON Representation
[
{
"page_id": "x" | "x.1" | "x.2",
"text": ["line 1", "line 2", ...],
"with_regions": [
{"text": "line 1", "bbox": [x0, y0, x1, y1]},
{"text": "line 2", "bbox": [x0, y0, x1, y1]},
...
],
"image_path": "<working dir>/processed_images/<job_i>/PAGE1.jpg",
"error": null | "error string"
},
...
]